Linear SVM
The loss function for a logistic regression model is given by
![\[L = - [ \hat{y}\log{y} + (1-\hat{y})\log{(1-y)} ]\]](http://www.ssravisutha.com/wp-content/ql-cache/quicklatex.com-c0839603c00a9d4b75e2c7f2158eac8d_l3.png "Rendered by QuickLaTeX.com")
The output of the logistic regression is defined as
![\[y = \frac{1}{(1 + e^{w^Tx})}\]](http://www.ssravisutha.com/wp-content/ql-cache/quicklatex.com-c8ce090a21c493d2cc14e9f722de6f76_l3.png "Rendered by QuickLaTeX.com")
Ideally, the weights should be as low as possible. To do so, we employ L2 regulrization. This also has a side effect of weight decay where the weights for non-contributing features tends to zero.
![\[L = -[\hat{y}\log{y} + (1-\hat{y})\log{(1-y)}] + \frac{\lambda}{2} ||w||^2\]](http://www.ssravisutha.com/wp-content/ql-cache/quicklatex.com-7c5ca627838e84b0d2d090e2bbb4a8d7_l3.png "Rendered by QuickLaTeX.com")
where  is a regularization parameter.
is a regularization parameter.
The functions log(y) and log(1 - y) can be replaced by approximated cost functions.
![\[L = y\cdot cost_1(w^Tx) + (1 - y) \cdot cost_0(w^Tx) + \frac{\lambda}{2} ||w||^2\]](http://www.ssravisutha.com/wp-content/ql-cache/quicklatex.com-144b843924dd40b48f7053e42ff5082a_l3.png "Rendered by QuickLaTeX.com")
Now, divide L by .
Let
. Then
![\[L = \frac{1}{\lambda}(y \cdot cost_1(w^Tx) + (1 - y) \cdot cost_0(w^Tx)) + \frac{1}{2} ||w||^2\]](http://www.ssravisutha.com/wp-content/ql-cache/quicklatex.com-9e84954b23db29fa04c071637960df1b_l3.png "Rendered by QuickLaTeX.com")
![\[L = c(y \cdot cost_1(w^Tx) + (1 - y) \cdot cost_0(w^Tx)) + \frac{1}{2} ||w||^2\]](http://www.ssravisutha.com/wp-content/ql-cache/quicklatex.com-3e4fb5f97fbd2cfcafdccfaddade9c9c_l3.png "Rendered by QuickLaTeX.com")
This is equivalent to maximizing the margin which is given by  between hyperplane and the data points in both classes.
between hyperplane and the data points in both classes.
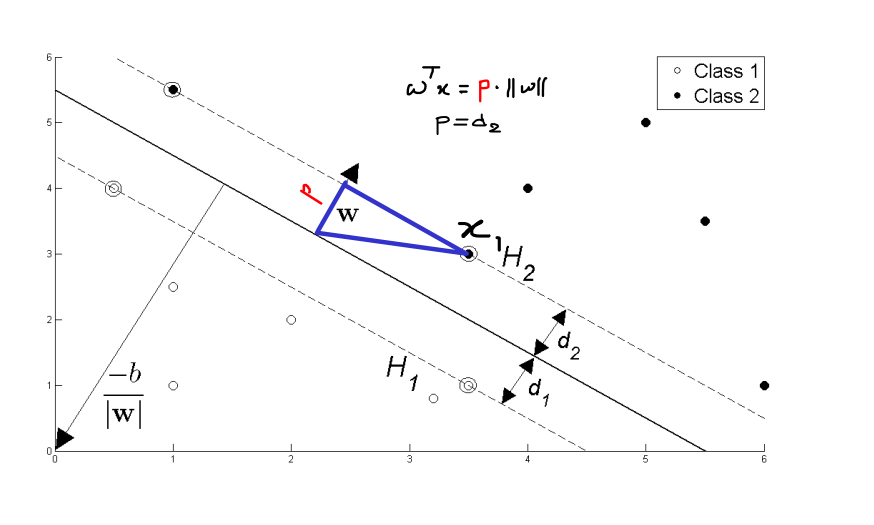
Here is how – Ideally,
![\[w^Tx_1 = 1\]](http://www.ssravisutha.com/wp-content/ql-cache/quicklatex.com-a924506fa84e434d4bf658329fa4f3c3_l3.png "Rendered by QuickLaTeX.com")
But this can be written as (from projection theorem)
![\[d2 \cdot ||w|| = 1\]](http://www.ssravisutha.com/wp-content/ql-cache/quicklatex.com-c44e92e48b4ff0d20fb9787c9f40b8a9_l3.png "Rendered by QuickLaTeX.com")
![\[d2 = \frac{1}{||w||}\]](http://www.ssravisutha.com/wp-content/ql-cache/quicklatex.com-3594b8ce50727683a6480c9736253924_l3.png "Rendered by QuickLaTeX.com")
The aim of SVM is to maximize the distance between i.e maximize d2. Hence it is equivalent to minimizing ||w||.
Kernel Trick
Instead of just  , one can use
, one can use  . Generally,
. Generally,  will be gaussian function and hence the input closer to
will be gaussian function and hence the input closer to Support Vectors gets activated and you try to minimize the cost function involving the kernels. The gaussian kernels are also called as Radial Basis Functions(RBF) because of the shape of the activation.
Extra Notes
The vector c is also called as lagrage multiplier. It is used to find the support vectors that maximizes the margin.
For complete explanation, refer to this link.